1. 被選用于檢驗的感官技術的實質是由具體研究的對象決定的。
2. 熟練的檢驗小組應請來進行可接受性判斷,相反,消費者檢驗小組不適于進行精確描述檢驗。
3. 樣品標簽應隨機以3位數編碼,以免產生偏見。
4. 樣品次序應隨機或平衡排列,以避免人為影響。
5. 在評價過程中,專家之間不互相影響干擾。
6. 味覺與嗅覺中的各個混合感官成分在一定范圍內會部分地相互抑制,因此,在相同濃度下,一個感官成分在復合產品中所感受到的強度往往比單獨品評時低。
7. 連續對嗅覺或味覺的刺激會導致反應降低,成為感官適應。
8. 許多人會混淆味覺和嗅覺,未經訓練的檢驗者會將口中揮發物的嗅覺誤認為是味覺。
9. 消費者對口味和香味的反應常常是一種整體的感覺,而訓練有素的專業人員則能夠進行進一步分析。上述整體感覺在未經訓練的受試者被問及某單個屬性時會產生糊涂效應(錯誤或表面印象),因為其他屬性的作用使得該屬性被夸大了。
10、當檢驗對象與參照物相似時,一般認為2-3點檢驗比3點檢驗更敏感,例如,如果參照物是一個生產歷史較長且經過大量現行評估的標準產品,則所檢驗的相似物的偏差范圍比較穩定。
11、當評價小組考察具體屬性時,必選檢驗更敏感,比如成對比較檢驗。相反,比較總體差別的綜合檢驗(如3點檢驗)會過低估計差別程度,因為檢驗樣本往往會忽視關鍵屬性。由于進行全面判別檢驗的話,只要求判斷產品間的相對差別而不是比較差別強度,因此,全面判別檢驗也不如具體屬性檢驗敏感,這是一種頑固的偏見,即只偏重比較差別而不是強度。
12、如果存在疲勞的問題,則可以減少檢驗樣本量。如果不存在疲勞問題,比如當二重標準檢驗可以完全為評價小組描述樣品性質時,則比使用單個參照物的檢驗(如2-3點檢驗)或無參照物的檢驗(如3點檢驗)敏感度更高。
13、多重檢驗可通過X2分析檢驗,對所預期的0、1或2校正選擇的概率檢驗及其觀察頻率。重復檢驗可選擇用于檢驗變量且當變量滿足要求時可進行組合。
14、評判感官差異的工具的選擇取決于其絕對級別:間接衡量,即通過區別檢驗,能夠被用于估計較小差別的感官數值,較大的差別則宜用直接評價法。
15、屬性越簡單則標度越精確。標度并非劃分序列,大多數商品判斷的排序(或評分)考慮到許多性質,通常是缺點,并傾向于將它們組合起來而且常常是概括性的。
16、人是很好的感官相對評價“儀器”,而對絕對評價而言則很差。這表明所有標度必須由對照樣通過儀器來確定,而這些標樣的感官值是可比的。
17、觀察者在產品評價過程中會根據參比樣的前后關系或組成情況自行調整標準,訓練可以避免這一問題,但此時訓練能使標度使用的穩定到什么程度還不清楚。大多數前后關系會造成較大的反差,例如,一個好產品與一個稍差的產品相比會顯得比原先好得多。
18、感官評價標度通常最好是測量排序,那樣就可以給出評分排序,但是要求不出現感官評價值正好在級與級交界的情況。當根據數據獲得結論或在參數統計檢驗后得出統計結論時,記住上述要求是有用的。
19、可以用非標記的檢驗欄標度來替代數字分類標度以避免數字引起的偏見,在這些標度中、與選擇媒介無關,就像在線條標尺上作記號一樣的數字或標記,但是這些標度應當給予最終的文字標記,從而對參比樣的一般框架設定評價的尺度。
20、類項標度和線性標度對產品判斷而言作用基本相同,可能會造成一些過高估計,特別是對消費者的普通群體而言,估計過高對要求靈活性和建立無限制標度的情形(如很強的三叉神經刺激)是有用的,此時,數據往往偏高(包含較高的離群值)。
21、簡單、基礎性的術語比由許多單個屬性組成的復雜術語更精確,對于組合性術語,評價小組將十分艱難地對屬性因子進行權衡。這種權衡是造成個體之間差異的來源,從而容易產生誤差。
22、評價小組應當對產品種類差別的敏感度以及在實際評價中會遇到的產品屬性進行篩選。
23、無論是以文字形式還是由參比樣標準得到的物理形式的術語,都應對評價小組定義清楚。
24、在重點評價實施之前,檢驗小組應當獲得一致意見(并通過統計方法檢驗),小組的共同意見關系到術語的定義以及用于強度判斷的參比樣的框架。
25、描述標度的最終定位必須是感官可行的,例如,如果一些產品完全沒有某種屬性則應在級別低的一段注明“全無”。
26、描述分析必須通過重復樣品來進行,以提供統計強度和檢驗評價小組行為的個體差異。
27、一般用術語“可接受”和“可接受性”來表示喜歡與討厭的程度,如同用典型的數字標度評估一樣。“偏愛”從另一方面而言是指在產品中進行挑選,而“排序”是用多重樣品進行偏愛檢驗的形式,排序并不表示評估。
28、偏愛檢驗比可接受性分級更敏感,這是普遍承認的,然而,證實這一觀點較為困難。此外,由于兩種產品可能都不被喜歡(偏愛則在這兩者之間還能選出較好的),因此,可接受性實驗數據所包含的信息更豐富,而且偏愛檢驗本身常常根據可接受性分級實驗得出結論。
29、對稱的9點快感標度很有效、靈敏,且是衡量可接受性的良好評價工具。
30、作出無偏愛的選擇很難滿意地操作且難以滿足普遍的要求,如果必須作出選擇的話,在作出無偏愛的結論同時往往附有一個在一定范圍內的偏愛。
31、消費者可接受性檢驗的對象應是所研究產品的真實消費者,觀察項目為使用頻率。
32、為了避免受試者問到一些沒有考慮過的屬性而產生偏見,應首先詢問一些總體意見的問題,然后再針對具體屬性進行調查,其程序是由概括性問題到具體問題。
33、調查時應詢問受試者比較了解的問題(他們會知無不言),要保持提問的簡單與直接。
34、采用無限制性問題時應注意其局限性:這類問題有利于言語表達自由的、反應性強的評價小組,但在編碼的轉譯與總結方面受到限制。
35、限制性選擇題(限定選擇項)應包括相互排斥與補充的對象。
36、對受試者進行預測驗是必要的。
37、家庭檢驗是消費者測試方法中最實用與最易實施的,但也最易受干擾、最昂貴及最不可靠,相反的是對中心地區居民進行測試,把其受試者當做“消費模特”(具有較高的可控性、可信度,而代表性較差)。
38、感官測試應縮小概念方面的問題,只要給予一定的概念性信息以保證產品使用正確以及表達正確的分類就足夠了。如果想獲得參比樣的進一步內容如組成成分,則須由消費者進行概念化產品測試。
39、不要指望無標簽感官測試與概念化產品市場調查檢驗的結果相同,它們各自目的不同,沒有絕對的對與錯。
40、集中小組面試對產品開發及其后期工作是有益的,例如,它們可用于創造術語(在描述和消費者使用中)、設計調查問卷以及后續的家庭測試中開展新的或未確定的項目。
41、對于偏高的數據或含較高離群值的數據,中間值或幾何平均值中間趨勢的適宜度量,但不是指算術平均值。對兩邊分布型的數據,均值的代表性也較差,這些數據應當用圖描述或表示。
42、無論何種場合,應使用有自身質量對照樣的對象,這意味著具有完整的設計(包含項目分析)。成對t檢驗幾乎總比組間(獨立t)檢驗靈敏,應為一個項目的判斷通常需要相互校正,上述原則的平行樣數量范圍要求一個完整的塊設計(如在方差分析的重復測定中,所有評價小組成員評價所有的產品)比包含評價不同產品進行組間比較的替換設計更靈敏。
43、在這些設計中,包含的評價小組成員之間的差異能夠容易地從整體誤差中分離開來,從而提高檢驗的敏感性。
44、評價小組成員的影響中一般不考慮其訓練度的影響,因為其不反映隨目的而變化的任何特定屬性的選取水平。因而正確的方差分析的誤差術語取決于評價小組成員因素的相互作用。
45、單側檢驗適用于判別和對差別分級,雙側檢驗幾乎適于其他所有檢驗,包括偏愛檢驗。
46、基準、空白或對照樣檢驗在某些設計中至關重要,它們在下列檢驗中采用以下形式:
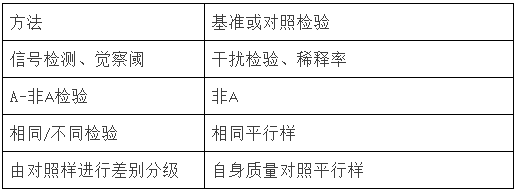
47、在下列情形時,應由儀器替代人工判斷:
(1)校正曲線已建立。
(2)重復、疲勞或危險的評價工作。
(3)從商業角度看數據結論不是至關重要的。
48、校正只在產品檢驗范圍內具有良好線性,因此,即使產品不工業化生產或銷售,極限值也必須包括在設計中,不具備清楚界限的較寬范圍就不能很好估計屬性的功能。
49、校正只在所用方法誤差置信范圍內具有良好線性,因此,良好的感官技術才能獲得相關性良好的儀器數據,相反,較差的或有缺陷的技術會妨礙良好儀器相關性的獲得。
來源:感官科學與評定,轉載請注明來源。
參考文獻:《食品感官評價原理與技術》(美)拉夫萊斯等著,王棟等譯. 北京:中國輕工業出版社,2001.6


