在偏愛檢驗中,消費者評定小組需要從一對產品或一組產品中選出最喜愛的一種,或對產品的喜愛程度進行排序。
一、成對偏愛檢驗
成對偏愛檢驗可能是第一種正式用來評定偏愛度的感官測試方法。成對偏愛檢驗的適用范圍較廣,因為該方法主要依靠評價員的直覺,而選擇又是消費者行為的基本要素,因此評價員可以很容易理解檢驗的任務。評價員能夠同時比較兩個樣品,也可能進行一系列的兩兩比較。而且,當消費者評定小組只有很低的閱讀能力或者很低的理解能力時,這項技術也會做得非常好。同時成對偏愛檢驗也是容易組織和執行的,它只有A-B和B-A兩種上樣次序,測試人員在一次測試當中通常只需要評估一對產品。成對偏愛檢驗一般是雙尾檢驗,因為我們無法提前知道哪個產品會更受到喜愛。
應注意的是,在進行成對偏愛檢驗時,應只讓消費者回答一個問題,即偏愛哪個產品;而不能再詢問他們選擇的理由。
必選成對偏愛檢驗就是強迫評價員在兩個樣品間做出選擇,不允許“無偏愛”結論。在該方法中,評價員收到2個編碼的樣品,這兩個編碼的樣品被同時呈送給評定小組,要求評定小組鑒別出更受偏愛的樣品。其計分卡示例見下表。

這種偏愛檢驗方法所獲數據的分析可采用計算二項式概率或X2檢驗或基于正態分布的比例Z檢驗。所有這些分析都假設評定小組被強迫做出選擇。
在上面所描述的所有數據分析中,均假設受試者都被迫表明他們對一個產品的偏愛。非必選偏愛檢驗與必選成對偏愛檢驗相同,均呈送給評價員兩個編號的樣品,要求其選出喜愛的一個樣品,但該檢驗允許“無偏愛”選項或“同樣喜歡”和“同樣不喜歡”選項的出現,當評價員認為對兩個樣品的喜愛程度無差異時,不需要被迫做出選擇。因此,該檢驗相對于必選成對偏愛檢驗來說具有一定的優勢,即評價員能夠按照自己的喜好做出真實的選擇。但是,非必選偏愛檢驗也會給評價員提供一種“比較容易”的想法:因為沒有必要必須做出選擇,所以不用努力做出選擇。


然而,增加選擇項的類別,數據的分析就不會像必選偏愛檢驗那樣簡單,因為建立在二項式、正態分布基礎上的數據分析方法都假設檢驗有一個必選,因此,非必選偏愛檢驗會使數據分析變得復雜。有以下三種選擇方式來處理數據:
選擇1:照常分析,忽略非偏愛選項的評估。但會減少可使用的研究對象數目,檢驗力會隨之降低。
選擇2:將非偏愛評估數目分割為50:50,這是假設如果使用非偏愛選項的受試者需要做出必選的話,他們就會隨便地選擇一個或另一個產品。由于此時樣本的數目仍維持在原來N個水平上,所以看起來是維持了原有的檢驗力;但實際上是降低了信噪比的比率。
選擇3:將非偏愛評估與保留的偏愛評估按比例地進行分配。假設使用非偏愛選項的受試者會選擇一個或另一個產品,類似于的確做出選擇的受試者。這個假設是建立在Odesky(1967)發現的基礎上,按照Odesky的說法,允許“非偏愛”存在時,受試者偏愛產品A的程度超過B的比例與必選時受試者偏愛A的程度超過B的比例是相同的。例如,如果50%的樣品表現出非偏愛的性質,而其他50%中有30%選擇產品A,20%選擇產品B,Odesky的原則就表現為如果必須選擇的話,則有60%對40%的偏愛(3∶2的比率)。因此,非偏愛數據分析的解決辦法是按非偏愛與偏愛分離的比例分配選票。
二、偏愛排序檢驗
偏愛排序檢驗要求評價員按照偏愛或喜愛的下降或上升順序對若干樣品進行排序。在排序過程中,通常不允許兩個樣品相等的結論存在,因此,該檢驗其實是多次成對必選檢驗。成對偏愛檢驗可看作是偏愛排序檢驗的子集。偏愛排序檢驗對視覺和觸覺的偏愛排序更加適用。因為對風味或品嘗進行排序易使消費者疲勞。下圖是偏愛排序檢驗的計分卡實例。對該檢驗所獲數據可使用Basker修改表(Basker,1998a,1998b)或Friedman 檢驗(Gacula和Singh,1984)進行分析。Basker修改表需要強迫評定小組做出選擇,而且它沒有固定的序列;Friedman檢驗能允許少量固定的意見。

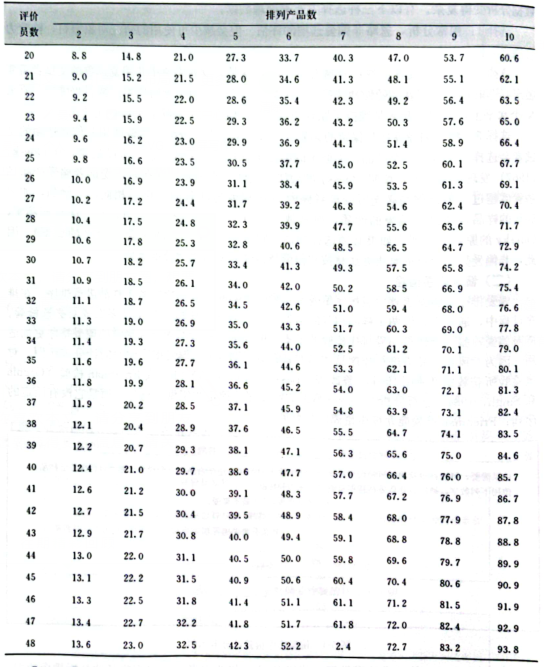
使用Basker修改表可以迅速而容易地分析排序數據。具體方法是給每個排序一個數值,接著將每個產品的排序數值加起來,然后計算每兩個樣品之間的排序和的差,最后對照Basker修改表中的排序和之差的臨界值(見下表),以判斷樣品之間的偏愛排序是否有差異。若排序和的差大于或等于臨界值,則樣品間具有顯著性差異。
Friedman檢驗的方程是建立在X2分布的基礎上,見下式。
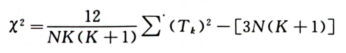
式中:K———樣品數;
N——評定小組的人數;
Tk——排序和。
X2的自由度為K一1。
如果X2檢驗測定出檢驗具有顯著性,接著就要進行各樣品排序總數的比較,以判斷在偏愛檢驗中哪一個樣品與其他另一個有差別,采用計算“最小顯著性排序差別”(LSRD)來判斷兩樣品之間是否在排序上有差異,方法為將兩樣品之間的排序和之差與LSRD進行比較,若兩個產品的排序和之差大于LSRD,表明這兩個產品間有差別,否則無差別。
LSRD計算公式如下:


